
Hi, I am Wentao Hu, a Master's student in the College of Computing and Data Science (CCDS) at Nanyang Technological University (NTU), advised by Prof. Hanwang Zhang in Mreal Lab. Before that, I earned my Bachelor's degree in Statistics from Hunan University(HNU).
My research interests lie in Multimodal Large Language Model, I'm also interested in AI agents.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Nanyang Technological UniversityCollege of Computing and Data Science
Nanyang Technological UniversityCollege of Computing and Data Science
M.Eng. StudentAug. 2023 - present -
 Hunan UniversityB.S. in StatisticsSep. 2019 - Jun. 2023
Hunan UniversityB.S. in StatisticsSep. 2019 - Jun. 2023
Experience
-
 Central Media Technology Institute(Singapore), Huawei 2012 laboratoryAI Research InternAug. 2024 - May. 2025
Central Media Technology Institute(Singapore), Huawei 2012 laboratoryAI Research InternAug. 2024 - May. 2025 -
 Kuaishou TechnologyInternDec. 2022 - Feb. 2023
Kuaishou TechnologyInternDec. 2022 - Feb. 2023
Publications
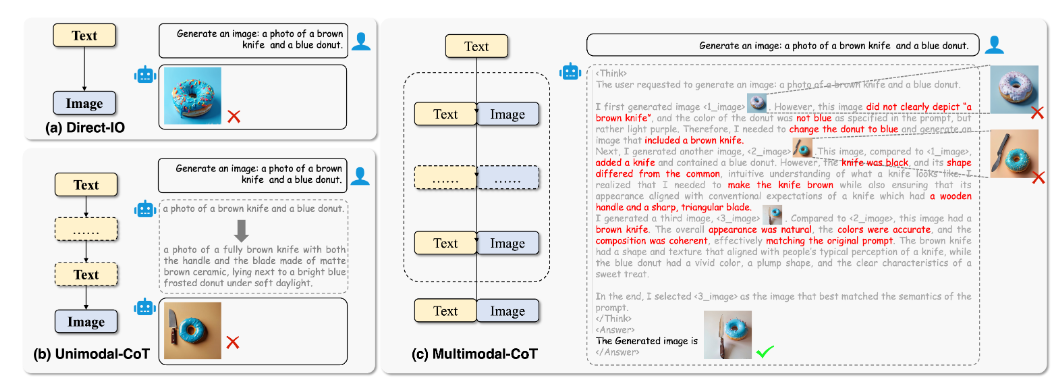
Vinci: Deep Thinking in Text-to-Image Generation using Unified Model with Reinforcement Learning
Wentao Hu*, Wang Lin*, Liyu Jia, Kaihang Pan, Zhang Majun, Zhou Zhao, Fei Wu, Jingyuan Chen, Hanwang Zhang (* co-first authors)
NeurIPS 2025(Poster),
Vinci: Deep Thinking in Text-to-Image Generation using Unified Model with Reinforcement Learning
Wentao Hu*, Wang Lin*, Liyu Jia, Kaihang Pan, Zhang Majun, Zhou Zhao, Fei Wu, Jingyuan Chen, Hanwang Zhang (* co-first authors)
NeurIPS 2025(Poster),
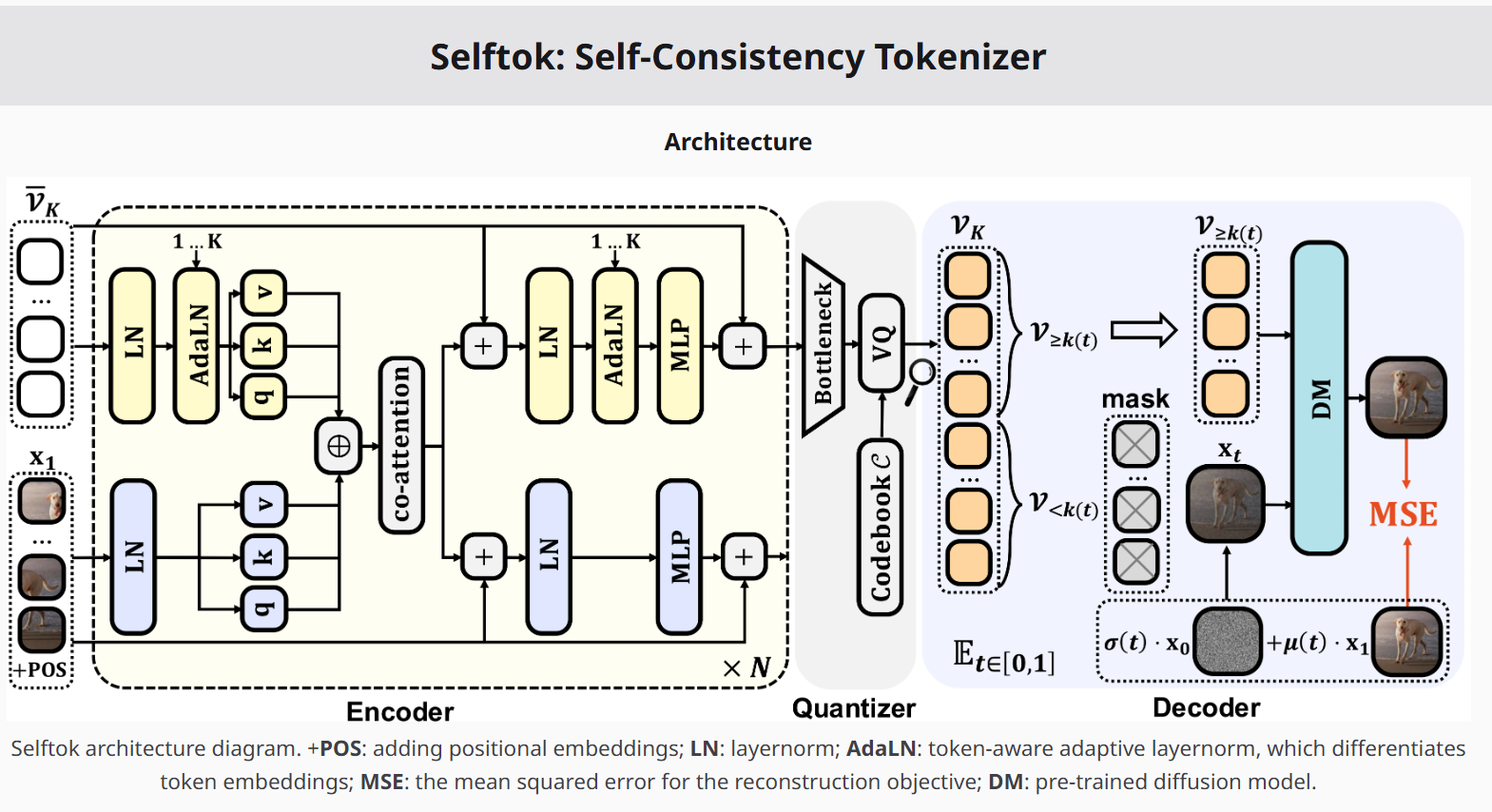
Selftok: Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
Bohan Wang, Zhongqi Yue, Fengda Zhang, Shuo Chen, Li'an Bi, Junzhe Zhang, Kennard Yanting Chan, Jiachun Pan, Weijia Wu, Mingze Zhou, Wang Lin, Kaihang Pan, Saining Zhang, Liyu Jia, Wentao Hu, Wei Zhao, Hanwang Zhang
NeurIPS 2025(Poster),
Selftok: Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
Bohan Wang, Zhongqi Yue, Fengda Zhang, Shuo Chen, Li'an Bi, Junzhe Zhang, Kennard Yanting Chan, Jiachun Pan, Weijia Wu, Mingze Zhou, Wang Lin, Kaihang Pan, Saining Zhang, Liyu Jia, Wentao Hu, Wei Zhao, Hanwang Zhang
NeurIPS 2025(Poster),
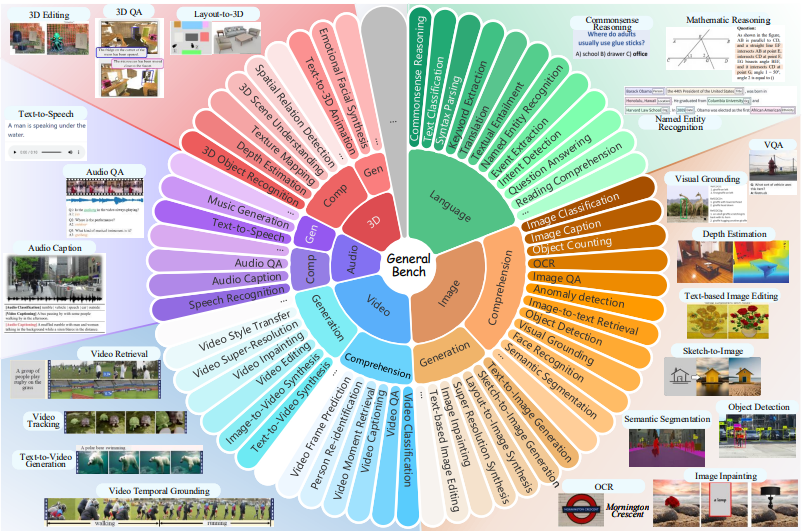
On Path to Multimodal Generalist: Levels and Benchmarks
Hao Fei, Yuan Zhou, Juncheng Li, Xiangtai Li, Qingshan Xu, Bobo Li, Shengqiong Wu, Yaoting Wang, Junbao Zhou, Jiahao Meng, Qingyu Shi, Zhiyuan Zhou, Liangtao Shi, Minghe Gao, Daoan Zhang, Zhiqi Ge, Siliang Tang, Kaihang Pan, Yaobo Ye, Haobo Yuan, Tao Zhang, Weiming Wu, Tianjie Ju, Zixiang Meng, Shilin Xu, Liyu Jia, Wentao Hu, Meng Luo, Jiebo Luo, Tat-Seng Chua, Hanwang Zhang, Shuicheng Yan
ICML 2025(Oral),
On Path to Multimodal Generalist: Levels and Benchmarks
Hao Fei, Yuan Zhou, Juncheng Li, Xiangtai Li, Qingshan Xu, Bobo Li, Shengqiong Wu, Yaoting Wang, Junbao Zhou, Jiahao Meng, Qingyu Shi, Zhiyuan Zhou, Liangtao Shi, Minghe Gao, Daoan Zhang, Zhiqi Ge, Siliang Tang, Kaihang Pan, Yaobo Ye, Haobo Yuan, Tao Zhang, Weiming Wu, Tianjie Ju, Zixiang Meng, Shilin Xu, Liyu Jia, Wentao Hu, Meng Luo, Jiebo Luo, Tat-Seng Chua, Hanwang Zhang, Shuicheng Yan
ICML 2025(Oral),
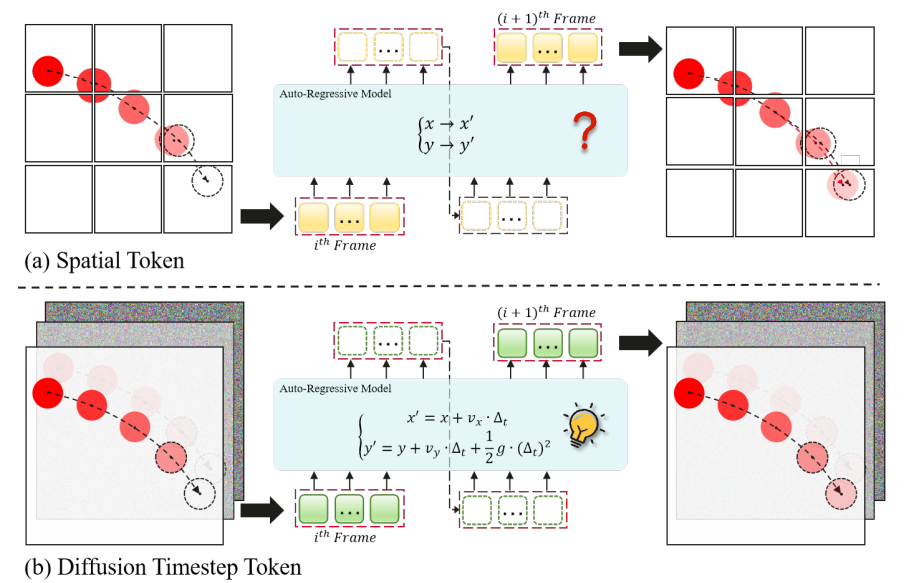
Reasoning Physical Video Generation with Diffusion Timestep Tokens via Reinforcement Learning
Wentao Hu*, Wang Lin*, Liyu Jia*, Kaihang Pan, Zhongqi Yue, Jingyuan Chen, Fei Wu, Hanwang Zhang (* co-first authors)
arXiv Preprint,Under Review 2025
Reasoning Physical Video Generation with Diffusion Timestep Tokens via Reinforcement Learning
Wentao Hu*, Wang Lin*, Liyu Jia*, Kaihang Pan, Zhongqi Yue, Jingyuan Chen, Fei Wu, Hanwang Zhang (* co-first authors)
arXiv Preprint,Under Review 2025